

The processing of large amounts of data is typical for data warehouse environments. Depending on the available hardware resources, sooner or later the point is reached where a job cannot be processed on a single processor resp. cannot be represented by a single process anymore. The reasons for that are:
- Time requirements demand the use of multiple processors
- Systems resources (memory, disk space, temporary tablespace, rollback segments, . . .) are limited.
- Recurrent errors require the repetition of the process.
Parallelization by RDBMS parallel processing
Modern database systems are capable of parallel query processing. Queries and sometimes also changes on large amounts of data can be parallelized within the database server and use multiple processors concurrently. Advantages of this solution are:
- No resp. only little development effort is needed
- Only a small overhead is produced by this kind of parallelization
Disadvantages are:
- The control of the degree of parallelization is very limited
- Changing the number of parallel executed processes at runtime is generally impossible
- In case of an error all work done so far is lost
- Required database systems resources (temporary tablespace, rollbaProcess Flow Control With Shell Scriptsck segments, . . .) must be appropriately dimensioned for the entire operation.
- The resource usage often isn’t deterministic which can lead to problems within systems with a strong need of resource control
- The influence of the parallelization on the rest of the system is very unpredictable resp. cannot be planned.
RDBMS parallel processing is therefore mainly suited for accelerating operations by the use of multiple processors. If systems resources aren’t abundantly present the disadvantages will be stronger noticeable. This is especially true for, in spite of parallelization, long running processes.
Parallelization at application level
Alternatively to RDBMS internal parallelization it is most of the time possible to split a process into several subprocesses which can be executed in parallel. Advantages of this solution are:
- Full control over the degree of parallelization is possible
- The number of active subprocesses at a certain time is dynamically adjustable
- Errors within one subprocess don’t (necessarily) invalidate the work of the other successfully executed parallel processes. The effects of errors on the total running time are reduced.
- Systems resources must only be available to satisfy the needs of the concurrently running processes.
- The resource usage can better be planned and the influence on the rest of the system is dynamically tunable
Disadvantages are:
- The implementation is very expensive without the support of an appropriate scheduling system
- The overhead for merging the results is typically higher than in case of RDBMS internal parallelization
The comparison of the advantages and disadvantages of the application based parallelization shows that especially for very expensive and long running processes in environments with limited resource availability the application based solution is preferable above the RDBMS internal parallelization. Particularly in data warehouse environments processes with these properties are frequently found.
Implementation
The implementation of application based parallelization always requires the next steps:
- Decomposition of a process into parallel executable subprocesses
- Implementation of the subprocesses
- Implementation of the control function of the parallel execution of the subprocesses
- Optionally the implementation of the merge-process of the partial results
Example:
In a data warehouse an SQL script exists which aggregates a very large partitioned database table and stores the result in a result-table. Because this process in the mean time requires more than the available TEMP space in the database, it has to be parallelized. The realisation of the first step mainly consist of creating a list of partitions and creating a subprocess for each partition. For the second step we use the original SQL script. We alter it in such way that the aggregation only accesses a single partition, specified by some parameter, instead of the entire table. The result is stored as an intermediate aggregate. After the execution of all parallel subprocesses we’ll have to aggregate the intermediate aggregate again and the result is stored in the result-table. The original SQL script also delivers a very usable template for this task. These steps can normally be implemented within only a few hours. The real problem of the realisation is the third step. If all advantages of the application based parallelization have to be gained, it is necessary to implement a control mechanism which provides at least the following functions:
- Execution and error recognition of the parallel subprocesses
- Control of the number of concurrent running subprocesses (at runtime)
- Monitoring and restart after an error of subprocesses
A considerable amount of know how is required for implementing an individual solution (scripting . . .). It will be very hard to achieve an efficient, stable and maintainable solution with acceptable costs. If the parallel subprocesses cannot be integrated in the used scheduling system, they evade the effective supervision and control within the operation of the data warehouse system.
No development effort is necessary for the realisation of the most difficult task
The BICsuite Scheduling system offers all functions for implementing the third step entirely. This way no development effort is necessary for the realisation of the most difficult task in this context. The largest barrier for parallelization of processes at application level is herewith disarmed.
Implementation within BICsuite Scheduling system with dynamic submits
The BICsuite Scheduling system allows jobs to start child jobs with varying parameters by using the BICsuite API. These newly created jobs are just as all other jobs visible withing the scheduling system. All functions (monitoring, operating, resource management, . . .) of the BICsuite Scheduling system are without restrictions available for handling these dynamically created job instances.
Back to the example:
Figure 1 shows the definition of a parallelizing process within the BICsuite Scheduling system.

As soon as the batch AGGREGATE is submitted for execution, both (static) child jobs SUBMIT PARTITIONS and AGGREGATE TOTAL are also instantiated and the job SUBMIT ARTITIONS can be executed. Because of the dependency (arrow in the figure) of SUBMIT PARTITIONS the job AGGREGATE TOTAL will only be executed first when the job SUBMIT PARTITIONS including all its child jobs has finished. The program for SUBMIT PARTITIONS is essentially the implementation of the first step of our list. It detects the partitions of the database table and creates using the BICsuite API (e.g.: command-line command ‘submit’) a child job for each partition. A simple implementation of the job SUBMIT PARTITIONS within a Unix environment could look like this (in this example the partitions are hardcoded, but also could
be the result of some query):
sh -c "for P in P1 P2 P3 P4 P5 P6 P7
do
submit --host $SDMSHOST --port $SDMSPORT --jid $JOBID \\
--key $KEY --job PARTITION --tag $P PARTITION $P
if [ $? != 0]; then exit 1; fi
done"
At the monitoring screen of the scheduling system, a running AGGREGATE batch looks like shown in figure 2.
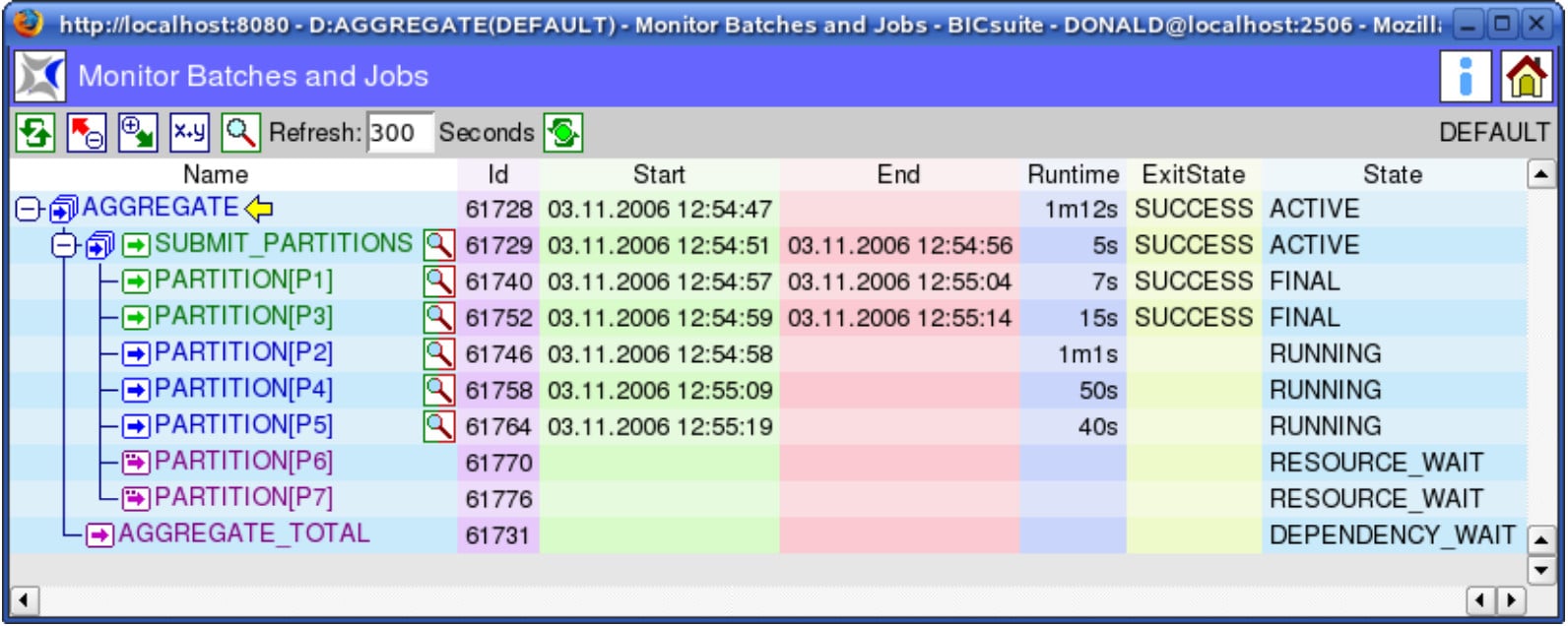
The BICsuite Scheduling system allows that every single AGGREGATE PARTITION Job can now be monitored and restarted (rerun) in case of an error. With only little effort can be controlled how many AGGREGATE PARTITION Jobs at a time can be executed at operating system level. This is simply done by defining a resource and a corresponding requirement. This number of parallel executed jobs can be altered at runtime. Figure 2 shows the batch with a maximum of three parallel AGGREGATE PARTITION Jobs. By defining additional requirements for other resources (used to map available system resources) for the AGGREGATE PARTITION Jobs, they also underly the rest of the resource management of the data warehouse operations.
The BICsuite Scheduling system allows with its dynamic submit functionality a fast, cost-effective, stable and maintainable implementation of application based parallelization. The parallel subprocesses are integrated in the entire process and become visible within the scheduling system. The overview and control over each of these subprocesses is therewith guaranteed at any time.